pytorch包含的组件
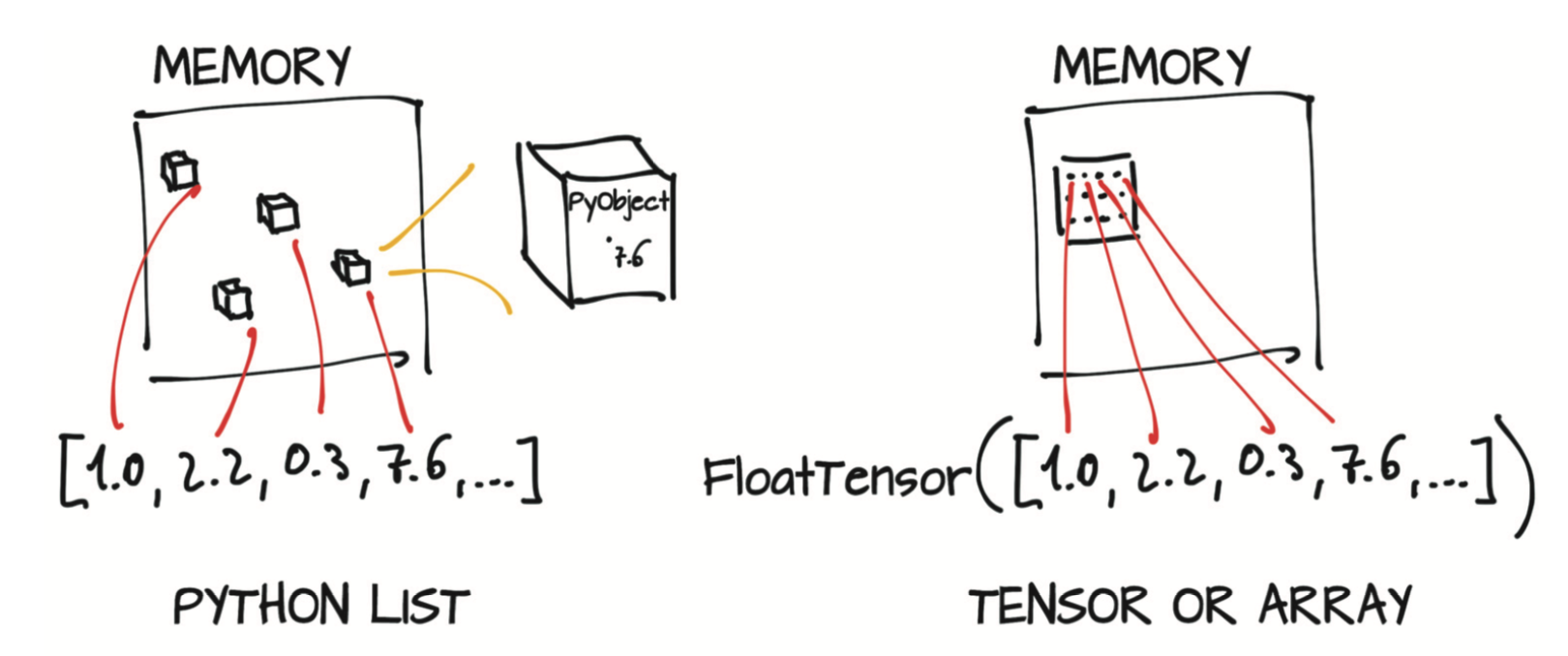
PyTorch的核心是提供多维数组的库,在PyTorch术语中这些多维数组称为张量(tensor),而torch模块则提供了可对其进行扩展操作的库。张量和相关操作都可以在CPU或GPU上运行。PyTorch提供的第二个核心功能是允许张量跟踪对其所执行的操作,并通过反向传播来计算输出相对于其任何输入的导数。此功能由张量自身提供,并通过torch.autograd进一步扩展完善。
PyTorch中用于构建神经网络的核心模块位于torch.nn中,该模块提供了常见的神经网络层和其他架构组件。全连接层、卷积层、激活函数和损失函数都能在该模块找到。为了训练该模型,你需要以下几点(除了循环本身以外,循环可直接采用标准的Python for循环):训练数据的资源、使模型能够适应训练数据的优化器以及将模型和数据导入硬件中的方法,该硬件将执行训练模型所需的计算。
torch.util.data模块能够找到适用于数据加载和处理的工具。需要用到的两个主要的类是Dataset和DataLoader。Dataset承担了你的自定义的数据(可以是任何一种格式)与标准PyTorch张量之间的转换任务。DataLoader可以在后台生成子进程来从Dataset中加载数据,使数据准备就绪并在循环可以使用后立即等待训练循环。
在最简单的情况下,模型将在本地CPU或单个GPU上运行所需的计算。因此,当训练循环获取到数据时就能够立即开始运算。然而更常见的情形是使用专用的硬件(例如多个GPU)或利用多台计算机的资源来训练模型。在这些情况下,可以通过torch.nn.DataParallel和torch.distributed来使用其他的可用硬件。
当模型根据训练数据得到输出结果后,torch.optim提供了更新模型的标准方法,从而使输出更接近于训练数据中的标签。
张量(Tensor)
PyTorch引入了一个基本的数据结构:张量(tensor)。张量是指将向量(vector)和矩阵(matrix)推广到任意维度,如下图所示。与张量相同概念的另一个名称是多维数组(multidimensional array)。

PyTorch并不是唯一能处理多维数组的库。NumPy是迄今为止最受欢迎的多维数组处理库,以至于它可以被当做数据科学的通用语言。事实上,PyTorch可以与NumPy无缝衔接,从而使得PyTorch能够与Python中的其他科学库(如SciPy、Scikit-learn和Pandas)进行高度的整合。与NumPy数组相比,PyTorch的张量具有一些更强大功能,例如能够在GPU进行快速运算、在多个设备或机器上进行分布式操作以及跟踪所创建的计算图。所有这些功能对于实现现代深度学习库都很重要。
在Python中可用list来存储和处理向量,但是效率很低:
Python中的数是完整( full-fledged)的对象。* 浮点数只需要32位就可以在计算机上表示,而Python将它们封装(boxes)在具有引用计数等功能的完整Python对象中。如果只需要存储少量数字,这种做法就没问题,但是要想分配数百万个这样的数字效率就太低了。
Python中的列表用于对象的有序集合。* 没有定义高效计算两个向量点积或向量求和的操作。此外,Python列表无法优化其在内存中的布局,因为它们是指向Python对象(任何类型,而不仅仅是数字)的可索引指针集合。最后,Python列表是一维的,尽管我们可以创建列表的列表,但这种做法仍然效率很低。
与经过优化和编译的代码相比,Python解释器速度较慢。* 使用可编译的低层语言(例如C)编写的优化代码可以更快地对大量数据进行数学运算。
由于这些原因,数据科学库依赖于NumPy或引入专用数据结构(例如PyTorch张量),这些结构提供了高效的数值数据结构的底层实现以及相关运算,并被封装成高级API。
1 | a = torch.ones(3) |
看起来这和python列表区别不大,但实际完全不同。python列表和元组是在内存中单独分配的python对象的集合,而pytorch张量和numpy数组(通常)是连续内存上的视图(view)。
- 二维张量
1 | >>> p = torch.zeros(3,2) |
张量存储
它的使用方法和numpy数组类似。数值分配在连续的内存块中,由torch.Storage实例管理。存储(Storage)是一个一维的数值数据数组,例如一块包含了指定类型(可能是float或int32)数字的连续内存块。多个张量可以索引同一存储,比如一个$2\times 3$的张量和$3\times 2$的张量。
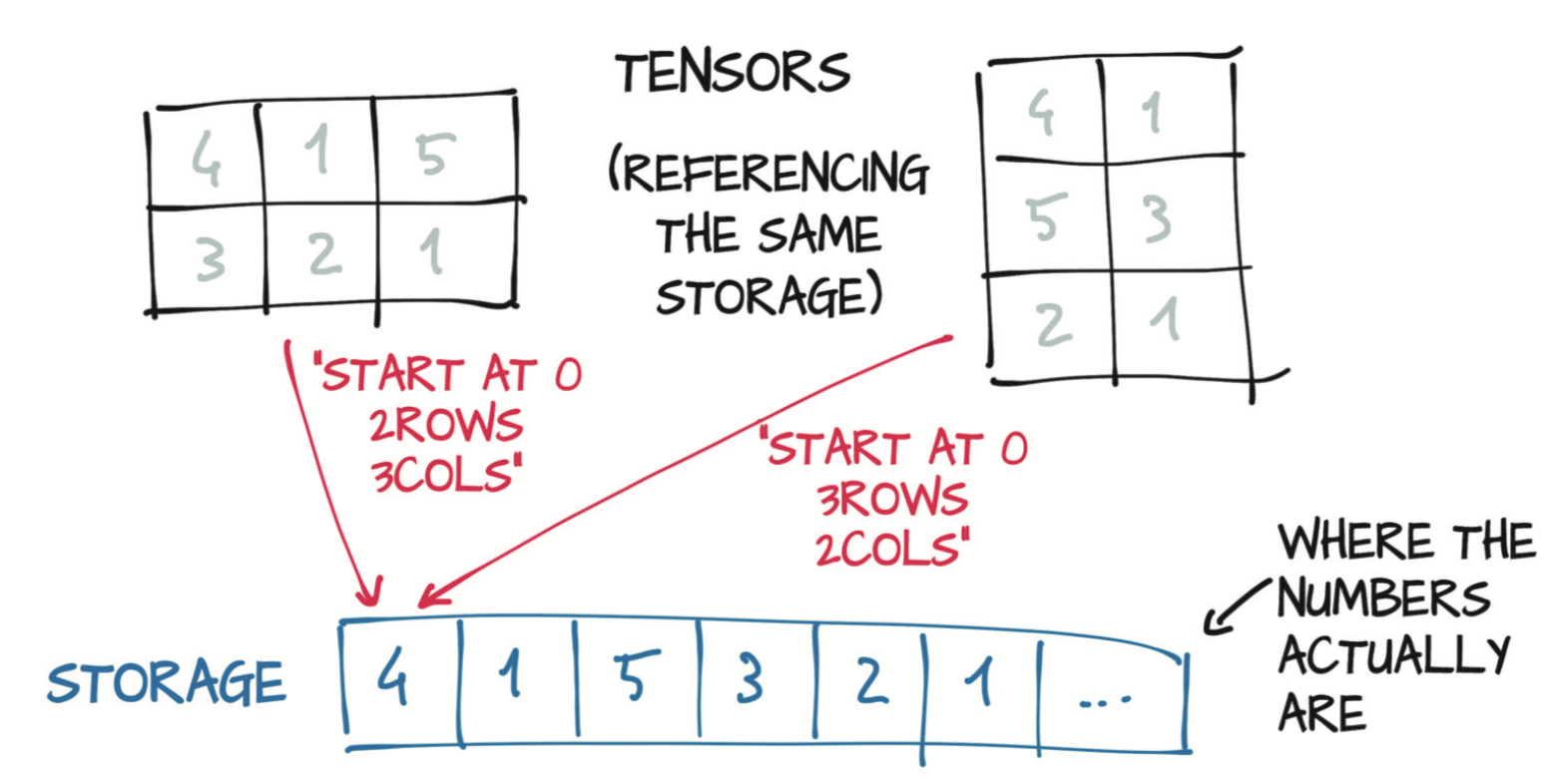
如图,storage始终是一维的,张量根据不同的张量维度来查找其数据。
1 | p[2].storage_offset() |
张量的偏移指的是在存储中相对于第一个点的位移量,索引正是这样找到其在storage中的地址。stride是步长,步长是一个元组,表示当索引在每个维度上增加1时必须跳过的存储中元素的数量。上面第一维数据每维有两个元素,因此步长是2.
张量和存储之间的间接操作会使得某些操作(如转置或提取子张量)的代价很小,因为它不需要重新分配内存,只需分配一个具有不同尺寸、偏移和步长的新张量。例如p[2] 是一个新的张量,它的shape是$2\times 1$ ,偏移是 4,步长是$(1,\;)$。它的维度减少了一个,同时可以看到索引在原来的存储上,因此改变子张量也会改变原始张量。
如果不希望改变原始张量的话,可以通过克隆的方式
1 | p_copy = p[2].clone() |
下面是转置的效果
1 | p |
它们不同的仅仅是尺寸和步长而已。这理解起来也比较显然,原始张量在对应维度上按步长增加就能访问到该维度下一个元素。因此转置的时候,只需将对应维度的尺寸和步长交换即可。
对于更高的维度
1 | s = torch.ones(3,4,5) |
连续存储
在上面的例子中,原张量是连续的(contiguous),但是转置不是,它只改变了形状和步长参数,但用的是原来的存储。可用contiguous()将非连续张量连续化,它对storage进行了重排。
1 | >>> p |
类型转化与索引
- pytorch的数据类型与Numpy兼容,可使用多种方法创建确定类型的张量,也可以通过type方法将一种类型的张量转换为另一种类型。
1 | p = torch.ones(10,2, dtype = torch.double) |
- pytorch的索引方法与Numpy基本相同,可通过切片来进行区间索引。
1 | some_list[:] # 所有元素 |
- pytorch的张量与numpy的数组可以互相转换。
1 | #从张量p创建numpy数组 |
它返回尺寸、形状和数值类型正确的NumPy多维数组。有趣的是,返回的数组与张量存储共享一个基础缓冲区。因此,只要数据位于CPU RAM中,numpy方法就可以几乎零花费地高效执行,并且修改得到的NumPy数组会导致原始张量发生变化。
如果在GPU上分配了张量,(调用numpy方法时)PyTorch会将张量的内容复制到在CPU上分配的NumPy数组中。
相反,你可以通过以下方式从NumPy数组创建PyTorch张量:
1 | points = torch.from_numpy(points_np) |
from_numpy使用相同的缓冲共享策略。
模型张量的保存
PyTorch内部使用pickle来序列化张量对象和实现用于存储的专用序列化代码。
1 | torch.save(points, '../../data/chapter2/ourpoints.t') |
或者,你也可以传递文件描述符代替文件名:
1 | with open('../../data/chapter2/ourpoints.t','wb') as f: |
将points加载回来也是一行类似代码:
1 | points = torch.load('../../data/chapter2/ourpoints.t') |
等价于
1 | with open('../../data/chapter2/ourpoints.t','rb') as f: |
这个文件是pytorch特有的,用其他软件无法打开,如果想与其他库或环境使用,可以用HDF5格式和库,它以Numpy数组的形式接收和返货数据。
1 | conda install h5py |
使用h5py保存前需要将张量转换为numpy数组
1 | # 保存 |
张量转移到GPU运行
1 | points_gpu = torch.tensor([[1.0, 4.0], [2.0, 1.0], [3.0, 4.0]], device='cuda') #直接在GPU创建 |
相关API
首先,在torch模块下可进行张量上和张量之间的绝大多数操作,这些操作也可以作为张量对象的方法进行调用。例如,你可以通过torch模块使用先前遇到的transpose函数:
1 | a = torch.ones(3, 2) |
或者调用a张量的方法:
1 | a = torch.ones(3, 2) |
以上两种形式之间没有区别,可以互换使用。需要注意的是:有少量的操作仅作为张量对象的方法存在。你可以通过名称中的下划线来识别它们,例如zero_,下划线标识表明该方法是就地(inplace)运行的,即直接修改输入而不是创建新的输出并返回。例如,zero_方法会将输入的所有元素清零。任何不带下划线的方法都将保持源张量不变并返回新的张量:
1 | a = torch.ones(3, 2) |
输出:
1 | tensor([[0., 0.], |
- 创建操作 —— 构造张量的函数,例如
ones和from_numpy; - 索引、切片、联接和变异操作 —— 更改形状、步长或张量内容,例如
transpose; - 数学操作 —— 通过计算来操纵张量内容的函数:
- 按点(pointwise)操作 —— 将函数分别应用于每个元素(例如
abs和cos)的函数 - 简化(reduction)操作 —— 通过张量迭代计算合计值的函数,例如
mean、std和norm; - 比较操作 —— 用于比较张量的函数,例如
equal和max; - 频谱操作 —— 在频域中转换和运行的函数,例如
stft和hamming_window; - 其他操作 —— 一些特殊函数,例如对于向量的
cross,对于矩阵的trace; - BLAS和LAPACK操作 —— 遵循BLAS(Basic Linear Algebra Subprograms)规范的函数,用于标量、向量与向量、矩阵与向量和矩阵与矩阵的运算。
- 按点(pointwise)操作 —— 将函数分别应用于每个元素(例如
- 随机采样操作 —— 从概率分布中随机采样值的函数,例如
randn和normal; - 序列化操作 —— 用于保存和加载张量的函数,例如
save和load; - 并行操作 —— 控制并行CPU执行的线程数的函数,例如
set_num_threads;