基础
互相关运算与卷积
在深度学习中的卷积运算常常使用的是互相关来替代,免去了翻转卷积核的过程。
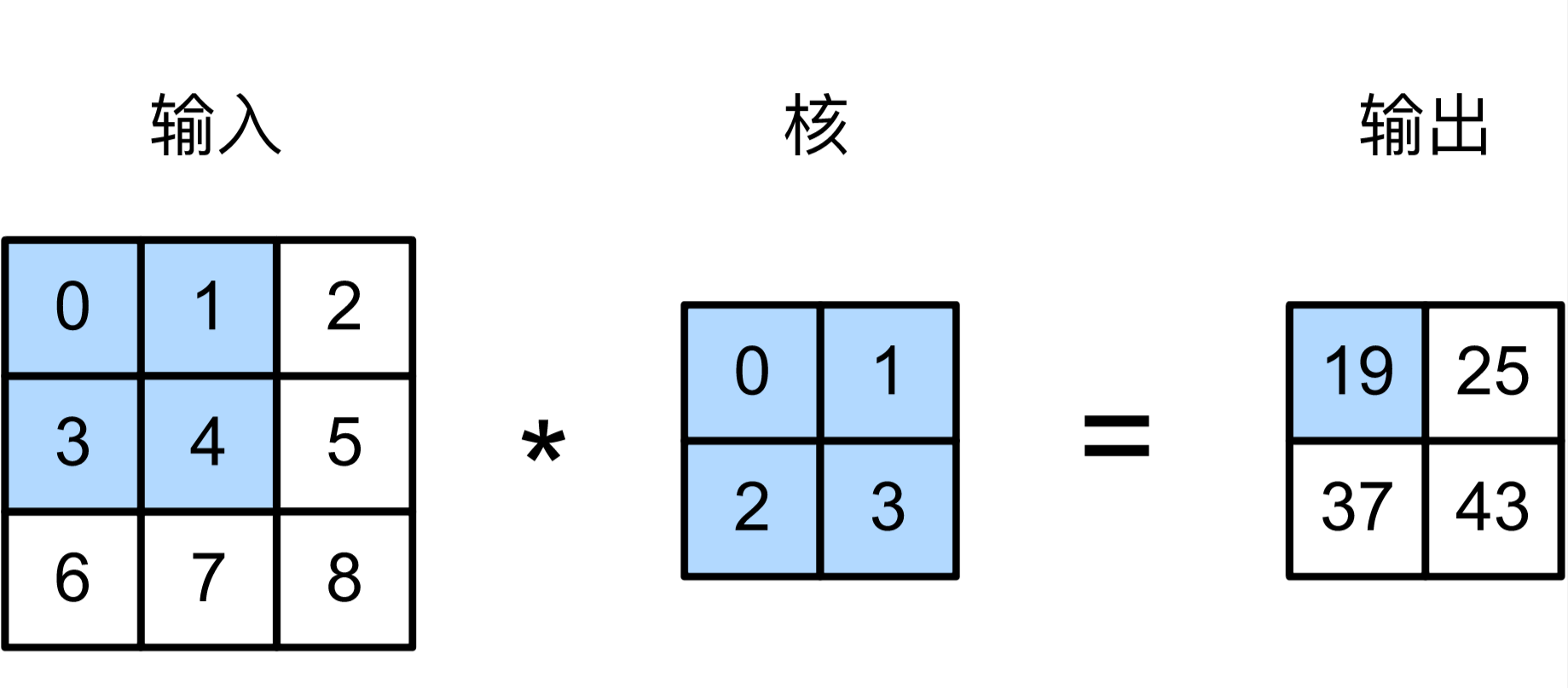
在二维互相关运算中,卷积窗口从输入数组的最左上方开始,按从左往右、从上往下的顺序,依次在输入数组上滑动。当卷积窗口滑动到某一位置时,窗口中的输入子数组与核数组按元素相乘并求和,得到输出数组中相应位置的元素。图5.1中的输出数组高和宽分别为2,其中的4个元素由二维互相关运算得出:
下面函数实现了这个互相关运算:
1 | import torch |
卷积层
继承Module定义一个卷积层
1 | import torch.nn as nn |
尝试通过Y训练来得到这个检测核
1 | # 构造一个核数组形状是(1, 2)的二维卷积层实例 |
输出:
2
3
4
5
6
7
>Step 10, loss 2.785
>Step 15, loss 0.698
>Step 20, loss 0.186
>weight: tensor([[ 0.9031, -0.8815]])
>bias: tensor([-0.0121])
>
得到weight参数接近前面定义的[1, -1] 卷积核
填充和步幅
- 填充
对于n n 的数据和 k k的卷积核,计算结果是 (n - k + 1) * (n - k + 1)的输出特征,也就是在每个维度会少k - 1个,当k是奇数时,少的就是偶数个。深度学习中常用的卷积核都是奇数的,正好可以在两端填充 (k - 1) / 2 个数据(常为0)来使得输出特征和原数据保持相同维度。
1 | import torch |
- 步幅
对于n n数据、k k卷积核、填充为k、步幅为s的一般情况,输出形状为:
若置p为常用的k - 1,则输出形状简化为:
如果输入的n 能被 s整除,那么形状为:
对于一般情况下,分子减去k加上步幅s可以理解为:初始便占用了k个大小的数据,它的输出为1个,加上步幅s便能让整除s后多1个。
例:
满足p = k - 1,(注意这里padding=1表示两边都添加1,因此k = 2 * padding),且s 能被 n整除,于是输出形状为 8 / 2 = 4
1 | conv2d = nn.Conv2d(1, 1, kernel_size=3, padding=1, stride=2) |
输出:
torch.Size([4, 4])
按照一般情况的公式,第一维: (n - k + p - s) / s = (8 - 3 + 0 + 3) / 3 = 8 / 3 ,下取整得2 ,第二维同理。
1 | conv2d = nn.Conv2d(1, 1, kernel_size=(3, 5), padding=(0, 1), stride=(3, 4)) |
输出:
torch.Size([2, 2])
多通道
- 多通道输入
当输入数据含多个通道时,我们需要构造一个输入通道数与输入数据的通道数相同的卷积核,从而能够与含多通道的输入数据做互相关运算。例如彩色图像具有3个通道。多通道卷积核只需将每个通道与对应的数据分别计算,最后将不同通道的特征对应相加即可。
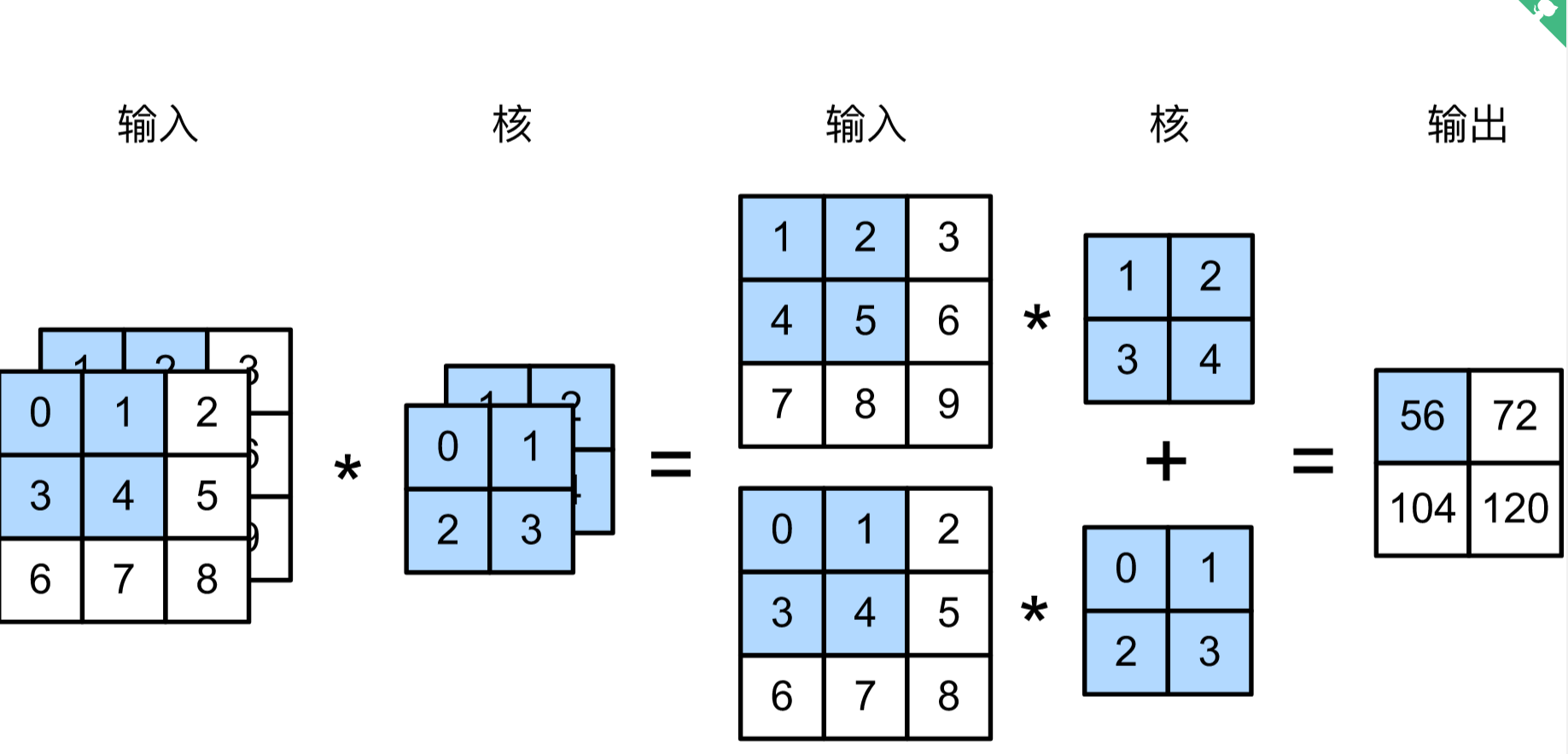
多输入通道的互相关计算:
1 | def corr2d_multi_in(X, K): |
输出:
tensor([[ 56., 72.],
[104., 120.]])
- 多输出通道
无论输入通道是多少维,输出都是1维通道。若要得到Co维的多通道的输出,则需在多输入通道卷积核的基础上,创建Co个多输入通道卷积核。将它们得到1维通道叠加得到Co维的多通道输出。
1 | def corr2d_multi_in_out(X, K): |
输出:
2
3
4
5
6
7
8
9
> [104., 120.]],
>
> [[ 76., 100.],
> [148., 172.]],
>
> [[ 96., 128.],
> [192., 224.]]])
>
- $1 \times 1$卷积层
$1 \times 1$卷积层常用与多通道情况,相当于把不同通道对应位置按权重加在一起。如果将不同通道看作特征维度,而输入h * w的数据看作一个单位样本,则$1 \times 1$ 卷积层相当于全连接层。
按照全连接层的思路,将输入通道看作特征维度,以全连接层的矩阵乘法来实现:
1 | def corr2d_multi_in_out_1x1(X, K): |
1 | X = torch.rand(3, 3, 3) |
输出是True,可以看出由全连接方式和1* 1卷积核得到结果是相同的。
因此,$1\times 1$卷积层可以被当作保持高和宽维度形状不变的全连接层使用。于是,我们可以通过调整网络层之间的通道数,控制模型复杂度。
池化层
池化的计算与卷积类似,不过在池化窗口中求最大或均值。仿照corr2d实现一个二维池化:
1 | import torch |
下面是使用nn模块中的最大池化:
1 | X = torch.arange(16, dtype=torch.float).view((1, 1, 4, 4)) |
- 多通道
池化中的多通道与卷积层不同,它的输出通道与输入通道保持一致,不会在不同通道之间求和:
1 | # 多通道 |
输出通道仍是2:
1 | tensor([[[[ 5., 7.], |
卷积神经网络(LeNet)
LeNet的网络结构如下:
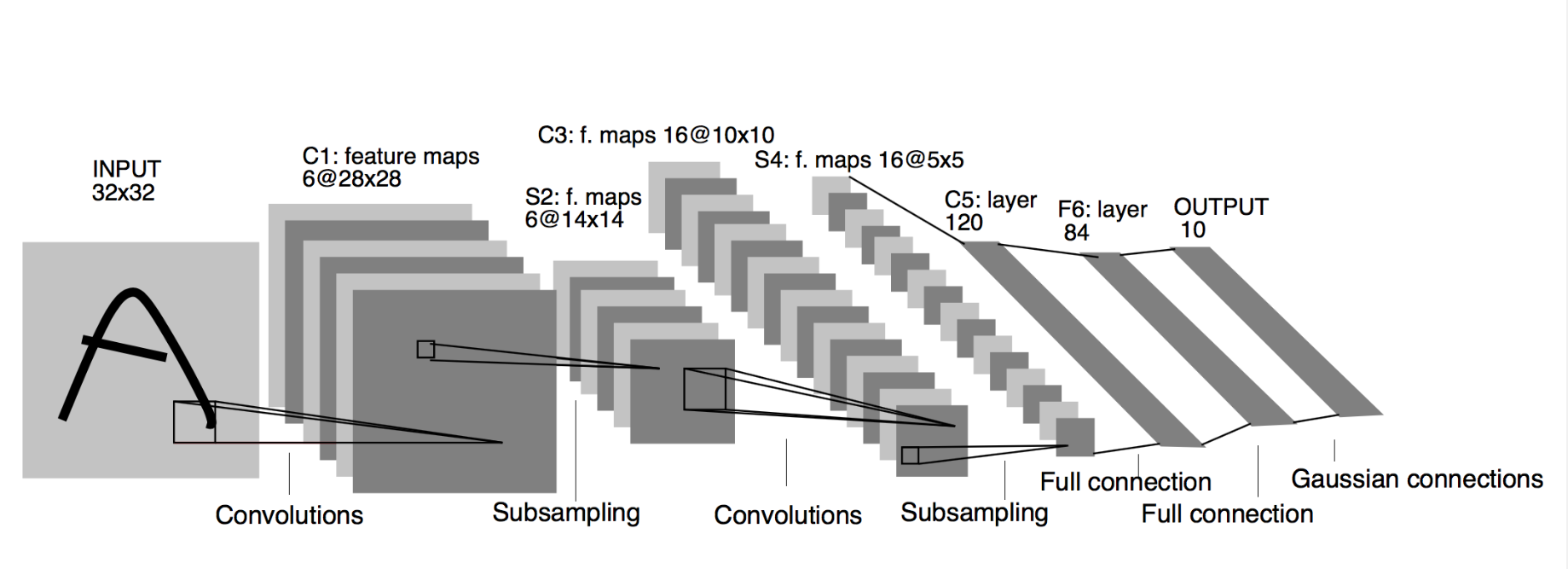
卷积层块里的基本单位是卷积层后接最大池化层:卷积层用来识别图像里的空间模式,如线条和物体局部,之后的最大池化层则用来降低卷积层对位置的敏感性。卷积层块由两个这样的基本单位重复堆叠构成。在卷积层块中,每个卷积层都使用5×5的窗口,并在输出上使用sigmoid激活函数。第一个卷积层输出通道数为6,第二个卷积层输出通道数则增加到16。这是因为第二个卷积层比第一个卷积层的输入的高和宽要小,所以增加输出通道使两个卷积层的参数尺寸类似。卷积层块的两个最大池化层的窗口形状均为2×2,且步幅为2。由于池化窗口与步幅形状相同,池化窗口在输入上每次滑动所覆盖的区域互不重叠。
卷积层块的输出形状为(批量大小, 通道, 高, 宽)。当卷积层块的输出传入全连接层块时,全连接层块会将小批量中每个样本变平(flatten)。也就是说,全连接层的输入形状将变成二维,其中第一维是小批量中的样本,第二维是每个样本变平后的向量表示,且向量长度为通道、高和宽的乘积。全连接层块含3个全连接层。它们的输出个数分别是120、84和10,其中10为输出的类别个数。
1 | import time |
PS:这里解释下在创建网络时,使用nn下的类和nn.functional下的函数的区别,一般来说,nn中 的类会自动帮我们维护模型需要训练的参数(weight、bias、stride等),而functional只是实现了对应的函数计算。因此functional更灵活,nn类会帮你管理参数。通常情况下,需要参数的(如conv2d, linear, batch_norm)用nn类,而不需要参数的(如maxpool, loss func, activation func)用functional。而dropout最好用nn,虽然它只是计算不包含参数,但是在nn定义下的model.eval()属性可以控制它的开关。
所以常常在net的继承Module方式搭建中看到nn被写在init()中,而functional方法被写在forward中。而对于使用Sequential方法搭建的网络,必须都是Module子类,所以只能用nn类。
数据读取,与之前相同
1 | import sys |
- 模型评估和训练
1 | # 模型评估 |
VGG网络
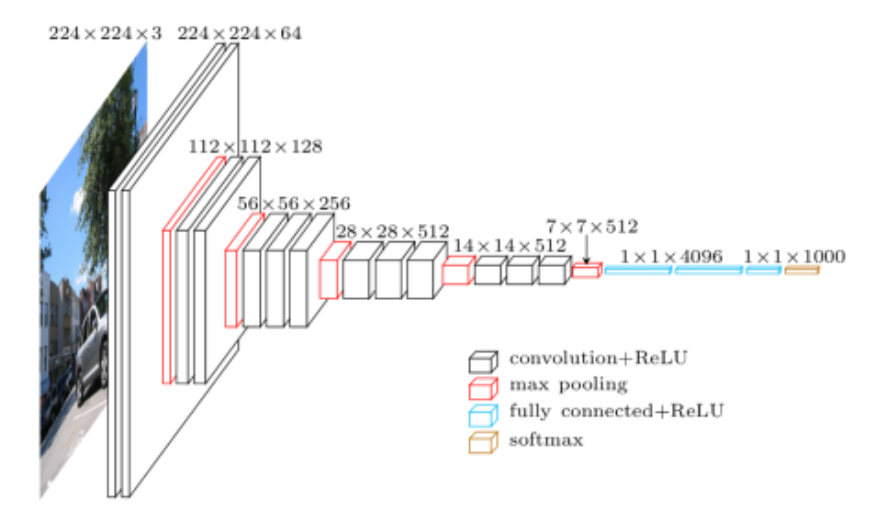
VGG块的组成规律是:连续使用数个相同的填充为1、窗口形状为3×33\times 33×3的卷积层后接上一个步幅为2、窗口形状为2×22\times 22×2的最大池化层。卷积层保持输入的高和宽不变,而池化层则对其减半。我们使用vgg_block函数来实现这个基础的VGG块,它可以指定卷积层的数量和输入输出通道数。
1 | def vgg_block(num_convs, in_channels, out_channels): |
VGG块就是VGG网络的主要特点,前面通过几个VGG块,后面添加全连接层便组成了VGG网络。
VGG网络:
1 |
|
输出:
1 | vgg_block_1 output shape: torch.Size([1, 64, 112, 112]) |
训练方法与之前相同
NiN网络
卷积层的输入和输出通常是四维数组(样本,通道,高,宽),而全连接层的输入和输出则通常是二维数组(样本,特征)。如果想在全连接层后再接上卷积层,则需要将全连接层的输出变换为四维。前面说过1×1卷积层可以看成全连接层,其中空间维度(高和宽)上的每个元素相当于样本,通道相当于特征。因此,NiN使用1×1卷积层来替代全连接层,从而使空间信息能够自然传递到后面的层中去。下图对比了NiN同AlexNet和VGG等网络在结构上的主要区别。
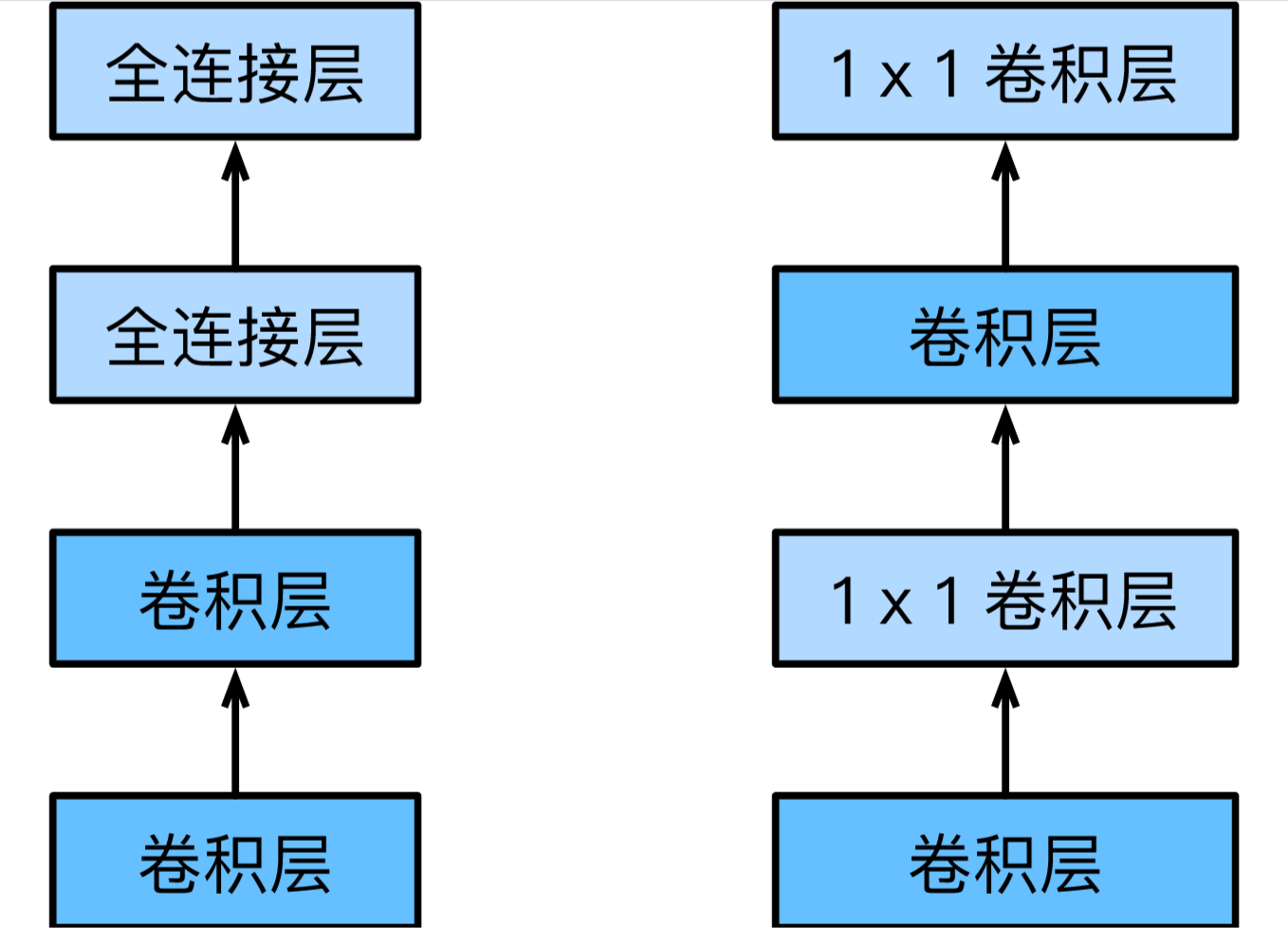
与VGG类似,NiN也有组成它的基础块,由一个卷积层加两个充当全连接层的1×1卷积层串联而成。其中第一个卷积层的超参数可以自行设置,而第二和第三个卷积层的超参数一般是固定的。
- NiN块
1 | def nin_block(in_channels, out_channels, kernel_size, stride, padding): |
- NiN网络
NiN是在AlexNet问世不久后提出的。它们的卷积层设定有类似之处。NiN使用卷积窗口形状分别为11×11、5×5和3×3的卷积层,相应的输出通道数也与AlexNet中的一致。每个NiN块后接一个步幅为2、窗口形状为3×3的最大池化层。
除使用NiN块以外,NiN还有一个设计与AlexNet显著不同:NiN去掉了AlexNet最后的3个全连接层,取而代之地,NiN使用了输出通道数等于标签类别数的NiN块,然后使用全局平均池化层对每个通道中所有元素求平均并直接用于分类。这里的全局平均池化层即窗口形状等于输入空间维形状的平均池化层。NiN的这个设计的好处是可以显著减小模型参数尺寸,从而缓解过拟合。然而,该设计有时会造成获得有效模型的训练时间的增加。
1 |
|
输出:
1 | 0 output shape: torch.Size([1, 96, 54, 54]) |
训练方法同上
GoogleNet
GoogleNet借鉴NiN串联网络的思想,提出了一种并联网络,它同样有一种基础块,叫做Inception块。如图:
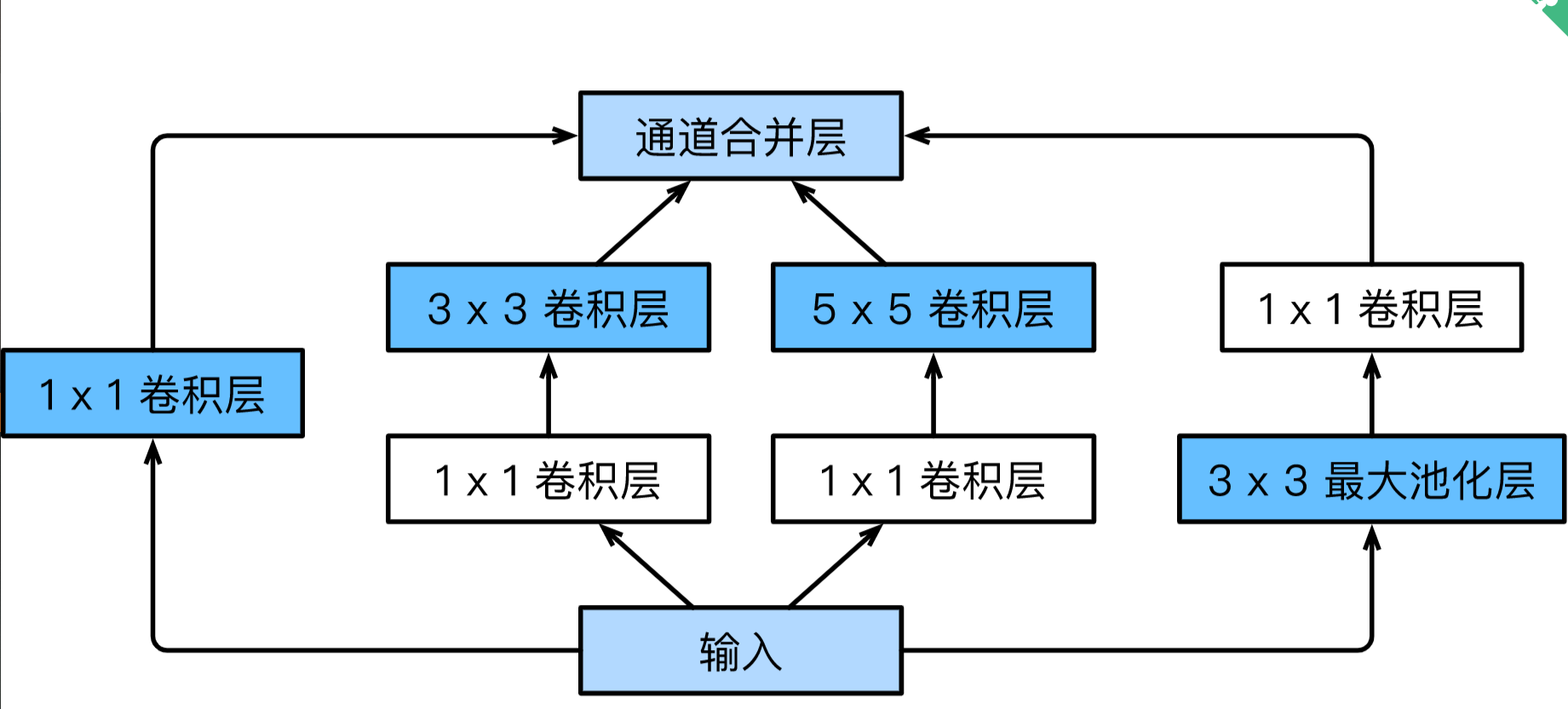
Inception块里有4条并行的线路。前3条线路使用窗口大小分别是1×1、3×3和5×5的卷积层来抽取不同空间尺寸下的信息,其中中间2个线路会对输入先做1×1卷积来减少输入通道数,以降低模型复杂度。第四条线路则使用3×3最大池化层,后接1×1卷积层来改变通道数。4条线路都使用了合适的填充来使输入与输出的高和宽一致。最后我们将每条线路的输出在通道维上连结,并输入接下来的层中去。
Inception块中可以自定义的超参数是每个层的输出通道数,我们以此来控制模型复杂度。
1 | import torch |
完整的GoogleNet网络包括了5个模块,
1 | # 第一模块使用一个64通道的7×7卷积层。 |
1 | net = nn.Sequential(b1, b2, b3, b4, b5, FlattenLayer(), nn.Linear(1024, 10)) |
输出
1 | output shape: torch.Size([1, 64, 24, 24]) |
批量归一化(batch normalization)
批量归一化层常用于激活函数之前,对全连接层来说,它位于仿射变换和激活函数之间。实际上就是先对一个批次的样本进行标准化后,再使用两个可学习的模型参数(拉伸和偏移),其形状与标准化后的数据相同。拉伸参数与数据按元素相乘,而偏移相加。全连接层和卷积层的标准化稍有不同,FC层标准化对于每个特征的所有样本,即对每个特征进行求均值和方差。而卷积层的通道相当于全连接层的特征,因此卷积层对通道进行求均值和方差,这就需要对样本、高、宽数据都进行求和。
手动实现BN
- 实现batch_norm函数,定义了BN计算,其中moving参数用于预测时作为全局均值和方差
1 | import time |
- BN网络模型,定义可训练参数
1 | class BatchNorm(nn.Module): |
1 |
|
输出:第一层学到的拉伸和偏移参数
1 | (tensor([1.1579, 1.0431, 1.1592, 1.0162, 1.1995, 1.1381], device='cuda:0', |
简洁实现
,Pytorch中nn模块定义的BatchNorm1d和BatchNorm2d类使用起来更加简单,二者分别用于全连接层和卷积层,都需要指定输入的num_features参数值。下面我们用PyTorch实现使用批量归一化的LeNet。
1 | net = nn.Sequential( |
ResNet(残差网络)
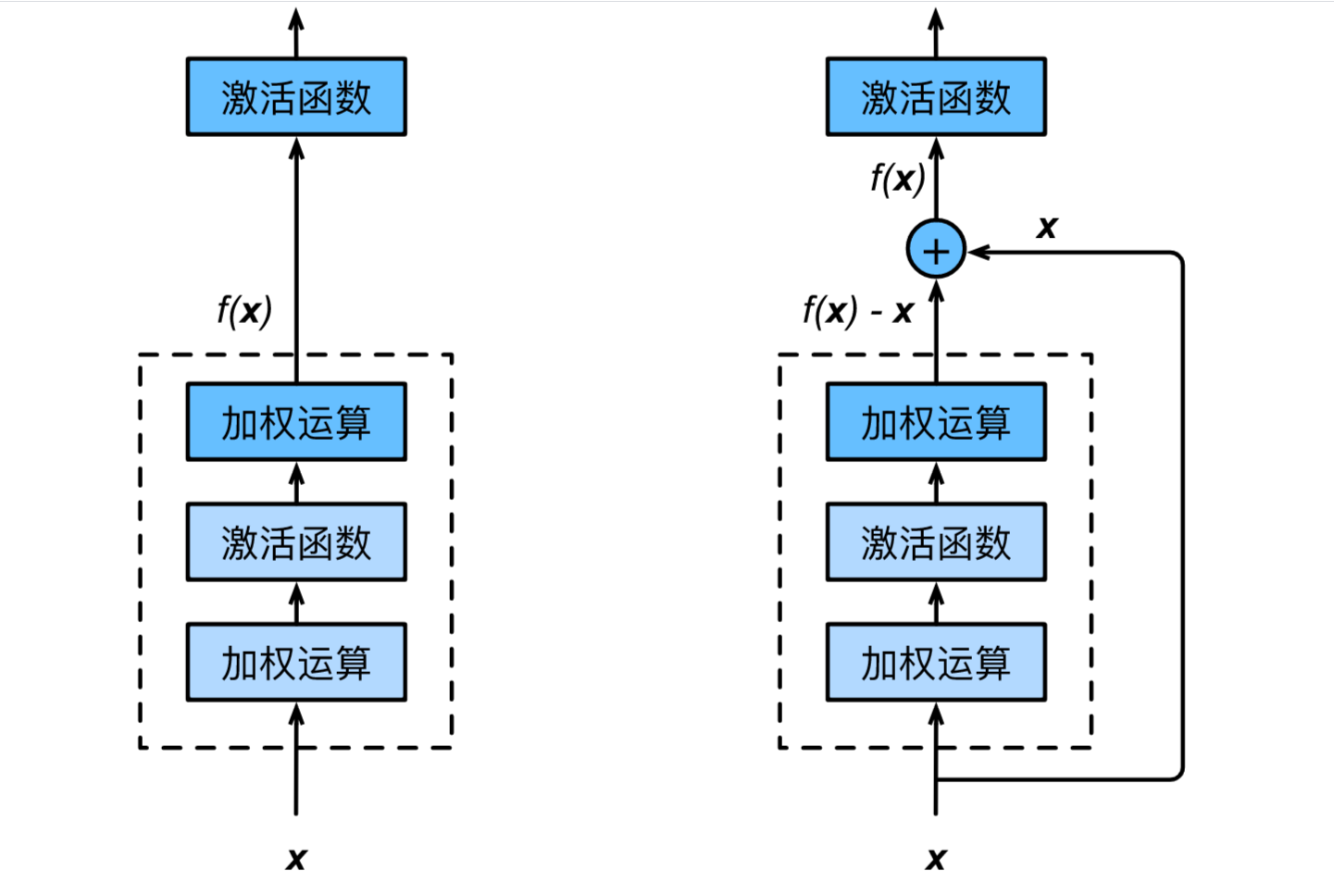
1 | class Residual(nn.Module): # 本类已保存在d2lzh_pytorch包中方便以后使用 |
ResNet构造与GoogleNet差不多,包含多个模块,其中前两个是正常模块,中间是由残差模块组成的,其中第一个模块输入输出通道相同,后面的模块依次让通道翻倍,高宽缩小一倍。且每个残差模块由2个残差网络组成。
1 | net = nn.Sequential( |
输出:
1 | 0 output shape: torch.Size([1, 64, 112, 112]) |
DenseNet
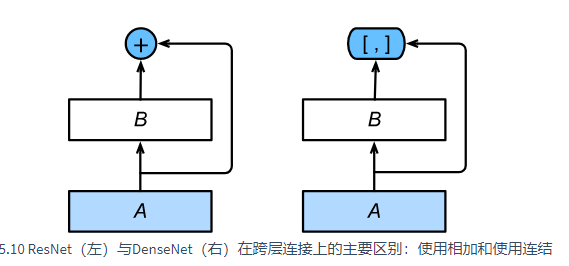
与ResNet的主要区别在于,DenseNet里模块BBB的输出不是像ResNet那样和模块AAA的输出相加,而是在通道维上连结。这样模块AAA的输出可以直接传入模块BBB后面的层。在这个设计里,模块AAA直接跟模块BBB后面的所有层连接在了一起。这也是它被称为“稠密连接”的原因。
DenseNet的主要构建模块是稠密块(dense block)和过渡层(transition layer)。前者定义了输入和输出是如何连结的,后者则用来控制通道数,使之不过大。
- Dense块
1 | # 单个卷积的固定模块 |
- 过渡层
1 | # 由于Dense块是串联的,过多使用会导致通道数过大,过渡层用1*1卷积减少通道数,并用步幅2减半高宽 |
- 实现DenseNet
与之前类似,都是将模块进行组合得到,且在前端后端用适当的输入输出处理层。
1 | import torch.nn as nn |
输出:
1 | 0 output shape: torch.Size([1, 64, 48, 48]) |
对比网络结构:
1 | Sequential( |