基础语法
1. python变量
- 变量定义
python是动态类型的语言,其变量声明不需要指明其数据类型,直接将对应的数值赋值给它即完成变量的定义。
1 | a = 10; |
- 变量与内存地址
与C语言变量名就是内存地址,对变量赋值就是改变该地址上的内容不同,python的变量赋值是改变内存地址使其指向数值为所赋值数值的地址,并不是原地址上数值的变化。这与C语言中的void *,和C++中的引用 & 很像。例如
1 | a = 10; |
执行完这几条语句后,变量a,b的地址相同,可用id(a)函数查看变量的地址。并且类型不同的变量之间也能直接赋值,这在C中是不允许的,所以说它类似与C中的void * 。实际上,python中普通numbers类型属于不可修改类型,因此num变量的改变是指向一个新的地址,而不是改变该地址的内容。
还可从函数调用中的内存变化来看其参数传递方式
1 | a = 10; |
通过查看变量地址发现,在函数调用过程中的局部变量x与原变量a的地址是相同的,赋值x=0时该变量的地址改变,指向值为0的地址,调用结束后该变量的地址又变了回来。
总结:python是动态类型语言,在运行时确定其变量类型。python变量与C中的void *和C++中的&很像,在赋值时,像指针一样直接指过去,并且可以跨类型赋值,这与void *属性一样,在函数传参时,直接传递变量地址,和C的指针和C++的引用一样。numbers是不可修改类型,改变时变化的是地址,类似指针和引用操作。
作为一个动态类型语言,python将其数据的类型归于该数据的这个对象,而变量名只拥有该对象的一个引用。变量名和对象之间可以看作一个绑定关系,绑定之后就可以通过对象来获取该数据的属性和方法。一个变量一次只能绑定一个对象,但是可以多次绑定不同类型的对象。python中,变量是一个指向对象的指针,给变量赋新值并不替换原来的对象,只是让这个变量去引用一个新的对象。
- 分支结构
python分支主要靠if语句
1 | if a<10: |
2. 集合
集合其实是一堆基本数据类型用特定的符号(通常是括号:圆括号、花括号、方括号等)将这堆数据作为一个整体来处理,在C语言里要求数据的类型必须一样,而可爱的Python较为宽容或者说不严谨,允许这一堆数据构造出的新类型里的各个数据的类型可以不一样。
常见的集合有列表list、字符串、元组tuple、字典dict、集set这几种。
- 有序与无序
有序是说某数据集合中的每个元素都有一个位置信息,通常用index表示,可以借助这种集合类型名和位置信息访问集合里的某元素值。其中,有序集合:list、string、tuple。无序集合:dict、set。
- 可修改与不可修改
可不可修改的意思即是该集合是只读的还是可以修改的。其中,可修改集合:list、dict、set。不可修改:string、tuple。
2.1 列表List
列表是python最常用的集合类,定义list的集合符号是方括号[ ] ,用逗号间隔每个元素,元素之间的类型可以不同。列表是一种有序且可修改的集合类型。
- 创建列表
- 用方括号直接创建
1 | a = [1, 2, 3] |
- 用list()函数将数据转化为list
1 | str = "string" |
- 列表访问与修改
前面说到,列表是有序的,那么就可以通过下标来访问其元素。
1 | s = 'python' |
对于列表li ,它有两个方向的下标(index),正向和负向。

负向下标可以大大方便从后向前访问的情形。列表除了有序,也是一个可修改的集合类型。通过下标访问到之后,便可以直接对其修改:
1 | a = 'python' |
- 列表的遍历
列表的遍历需要借助循环体,while或for都行。
1 | i = 0 |
2.2.1 列表相关函数
- index函数
列表index与字符串index一样,返回某值在集合里首次出现的位置。并且找不到会报错,然而列表没有字符串里的find函数去解决这一问题,一个解决方法是通过count函数或者in运算看列表是否有该值再使用index
- count函数
count函数可以统计某指定值再列表出现的次数。
- insert函数
在列表的某个位置插入一个指定数值的数,它帮我们将后面的数移动了。
1 | >>>a = [1,3,4,5] |
- append函数
在列表的尾部插入数据,一次性只能插入一个,但是可以插入列表,插入列表后就相当于C++中的二维向量。可以通过二重索引访问。
1 | >>>a = [1,2] |
- extend函数
上面的append函数一次性只能插入一个,使用extend可以一次性插入多个,类似于列表的合并。输入参数可以使元组或者列表
1 | >>>a = [1,2] |
- pop函数
pop函数可将列表指定位置或尾部的数据从列表删除,列表为空时使用会报错。其返回值是删除的值,默认情况删除尾部,若指定的index超出了列表范围也会报错
1 | >>>a = range(3) |
- sort函数
对列表元素进行排序。
- 小运用
将一个即包含列表,又包含单个数据的列表整理为一维列表。
ps: isinstance函数可以判断变量的类型,第一个参数是变量,第二个参数是类型,如果符合则返回True
1 | a = [1,2,[3,4],5] |
列表可以当作堆栈和队列使用,不过列表在尾部进行弹出和添加的效率高些,因为在头部操作需要将其他元素移动。因此列表可以很容易的实现堆栈,在列表尾部进行append和pop操作即可。
2.2 字符串
字符串是有序不可修改集合,即可用下标访问。用引号括起来,包括单引号、双引号和三引号(三个单或双)。字符串不可修改,但是可以拼接,可截取一串字符与另一串组合。
2.2.1 字符串运算符
1 | # 字符串连接 “+” |
PS: python2中,普通字符串是8位ASCII编码的,要使用16位的Unicode需要假设u前缀。而python3默认使用Unicode编码。
2.2.2 字符串函数
Python为字符串对象定义了许多有用的函数。下面总结几个常用的
- index与find函数
它们的作用都是在一个字符串中查找子串,用法都是一样的,唯一的区别是index在查找不到的时候会报错,而find查找不到会返回-1。它们的语法格式是
1 | Str.find(sub [, start [, end]]) |
sub是需要查找的子串,而start和end是可选参数,可以用来约束查找范围。
1 | >>>s = 'hello python' |
- replace函数
replace将字符串中的某子串替换成另一子串,返回值是新字符串,即不改变原字符串,产生一个新字符串。语法如下
1 | Str.replace(sub_old, sub_new[, count]) |
sub_old是要被替换的子串,sub_new是替换的子串,count是可选参数,代表从左到右替换几处。
- split函数
依据规则将字符串分割成列表,语法如下
1 | Str.split([sep [,maxsplit]]) |
它的参数都是可选参数,因此可以不含参数的调用,默认情况下以空格、回车、制表符等作为分割符号。后面的maxsplit代表分割成几个,没指定就能分多少分多少。
- strip函数
去掉字符串首尾的某些字符
1 | Str.strip([chars]) |
eg:
1 | >>>s = "%^!#pyt!#%on#!" |
2.3 字典
字典是一种无序可修改的集合,不能通过下标来访问集合中元素的值,它的访问与数据库中的键值对类似。不过它更灵活,可以存储任意类型的对象。字典的键和值用冒号分割,每个键值对之间用逗号分割,整个字典包括在花括号中,如下:
1 | dic = {key1 : value1, key2 : value2} |
其中,值可以取任意值,但是键必须是唯一的,并且键不可变。
1 | dict = {"cat" : 123, "dog" : "123", 123 : 456} |
其搭配都是任意的。
- 字典键的特性
键有两个重要的特征,一是唯一性,当创建时有两个相同的键时,后面的键值会被记住。二是不可修改,可用数字,字符串,元组充当,而可修改的列表就不行。
- 字典内置函数和方法
函数:
| 函数 | 描述 |
|---|---|
| len(dict) | 计算字典元素个数 |
| str(dict) | 输出字典,以可打印字符串表示 |
| type(variable) | 返回类型,对字典来说返回字典 |
方法:
| 方法 | 描述 |
|---|---|
| dict.clear() | 删除字典内所有元素 |
| dict.copy() | 返回一个字典的浅复制 |
| dict.formkeys() | 返回类型,对字典来说返回字典 |
| dict.get() | 与dict[key]作用相同 |
| dict.items() | 返回一个有key-value形式的元组组成的所有键值对的列表 |
- 字典的遍历
- 直接读键
1 | for key in dict: |
- 读值
1 | for v in dict.values(): |
- items直接返回key和value
1 | dict.items() |
注意items()返回的是二元元组组成的列表。
2.4 set
集Set的形式和字典很像,是无序集合,也是各个数据项用逗号间隔用花括号括起来,区别数据项不是一对儿,就是一个数据,且数据项的值不重复唯一。本章的这个Python数据类型真的和数学里的集非常相似,它既有基础的创建集合set、集合set添加、集合删除又有交集、并集、差集等操作。
集的创建可以用花括号赋值来实现,也可以用set函数创建。
1 | >>>s1 = {1, 2, 'a', 'all'} |
可以看到set中的数据没有重复的,且顺序与输入的顺序不一定保持一致。
2.4.1 set集的增删
集可修改,增加元素可用add和update函数。删除可用pop、discard、remove函数。
- 增加
add函数将输入的参数作为整体插入到set集中,而update会把传入的参数拆分,再插入到集中。例如传入一个字符串,add将其看作字符串插入,而update将字符串先拆分再传入。
1 | >>>s = set("abc") |
- 删除
pop函数没有参数,set是无序的,因此它随机删除一个(玄学),然后返回它的值。空集pop会报错。
discard函数可以删除集中某值,如果参数不属于该集则不进行任何操作。
remove函数和discard基本一样,区别在于不属于该集时会报错。
2.4.2 集的交集、并集、差集
交集:$A\cap B = \{ x|x \in A且x\in B \}$ 。可以用&运算或者intersection函数
并集:$A\cup B = \{ x|x\in A 或x\in B \}$。可以用 $|$ 运算符或者union函数。
差集:$A-B = \{ x|x \in A 且x \notin B \}$。可用 $-$ 运算符或者difference函数。
对称差集:$A\triangle B = \{ x|x\in A\cup B 且 x \notin A \cap B \}$。求对称差集可用^运算符或者用 symmetric_difference或symmetric_difference_update函数。
1 | >>>s = {1,2,3} |
集合虽然无序,但可用for循环来遍历,for会依次读取集合中的每一项。
2.n 切片Slice
切片是对有序集合进行的操作,目的是从有序集合中截取自己需要的那部分数据,构成子集和。切片需要控制的操作属性有起点start、终点end和步长step,注意步长是可以控制方向的,当步长为负时,则反方向进行截取。
先来看一个与切片原理相同的函数range()
1 | #函数语法 range(start, end[, step]) |
上面这些情况已大致可以看出该函数的性质,从start开始,以步长step为单位产生一个到end-1的列表。并且start和end的相对位置确定了产生数据的方向,若步长与之相反,则会生成一个空列表。比如range(1,3,-1),start到end方向是正向的,然步长为负向,因此切出来是空。
切片的表示是直接在列表方括号中给出范围:
1 | 切片子集名 = list_name[start: end[: step]] |
切片与该函数原理相同,不过range中start和end的负数并不是表示从后向前的下标,而是真正的负数。它们的默认步长都是1,可以不必明确指出。正常的切片与range相同,主要区别一下start和end负索引的情况
1 | >>>s = 'python' |
该图对应的情况如下
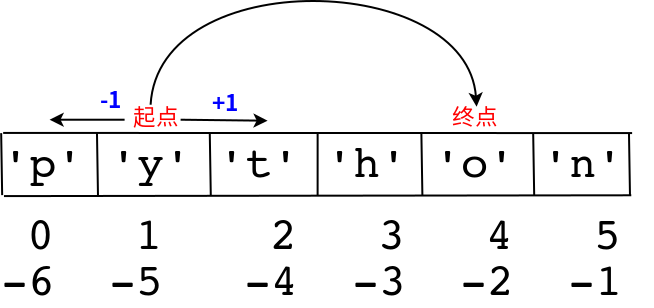
python会根据start和end的相对位置,判断子集的大致区域,再根据步长在该区域中选取最终的子集,步长若背离该区域,则会取到空集,另一个例子如下:
1 | >>>li[-1: 2: 1] |
对应情况如下

- 默认操作
有时根据应用情景,可以不必指出start、end或step。这时它们都有默认值,字符串string也是有序集合,可以对它进行切片:
1 | >>>s = "python" |
2. 循环
python中的循环包括while和for,其中while循环与C语言中的类似,但for循环与C语言有些区别。
while循环当满足条件时便循环,直到条件被破坏
1 | i = 0 |
当然,while循环可以实现无限循环
1 | flag = 1 |
for循环与C判断是否满足条件不同,python中的for循环每次从一个有序序列集合中取一个值赋给for关键字后的变量,直到该序列的数被取完为止。也就是该序列有多少个数值就循环多少次。
1 | for <variable> in <sequence>: |
python中的else会在执行完序列数量后的循环即将退出时执行一次else中的语句。for循环中的集合要求是有序的,即可通过下标访问,包括list、string、tuple。前面说的range函数可生成一串固定长度的有序列表,这一特性使得它经常与for循环搭配使用。
1 | for index in range(100): |
python的循环中也有break和continue语句,其效果和C语言中的相同。
3. 函数
3.1 函数定义
python的函数定义非常简单,因为是动态类型语言,它不需要指明函数返回值的类型。其定义的语法格式是:
1 | def function_name(parameter list): |
需要注意的是其函数内部没有括号来约束,和循环语句一样,需要通过前面加Tab来表示它是函数体内部的代码块。
3.2 参数传递
在第一节变量中讲到,python变量只是一个引用(指针),并没有类型,它可以指向不同类型的对象。然而在python的参数传递中,它却不能直接当作C++中的引用传递来理解。python的参数传递与该变量指向对象的能否修改有关,集合中讲到的list、dict、set是可修改的,而string与整数等是不可修改的。
对于python的参数传递:
- 可修改类型:类似C++引用,比如list传进函数,函数内部对list的修改会作用到外部的list本身。
- 不可修改类型:类似C++值传递,比如整数传进函数,对其修改只是影响到一个复制的对象,结束后会将变量名重新引用原来的地址。
3.3 参数类型
python的可用参数类型包括:
- 必需参数
- 关键字参数
- 默认参数
- 不定长参数
必需参数就是传参时必须输入和指定的参数,且顺序和数量需保持一致。关键字参数就是在调用时指定参数名,通过它可以使输入顺序不必按声明的顺序,比如
1 | def fun(pram1, pram2): |
如果在声明时为参数指定了一个默认值,那么在调用时可以不输入该参数,函数会自动为它赋默认值
1 | def fun(parm1 = "s", parm) |
不定长参数在不确定参数数量时可用,它有两种声明方法:
- 声明为元组(*)
1 | def fun([formal_args,] *args_ruple): |
在不定长参数前面仍可定义正常的参数,正常参数同前规范。带*的参数是不定长参数,对于后面输入的参数,python会把它保存在该元组中。当然,如果不输入多余正常参数的参数,那么它就是一个空元组。
1 | def printvar(arg1, *args): |
- 声明为字典(**)
1 | def fun([formal_args,] **args_dict): |
其调用如下
1 | fun(1,a=2,b=3) |
3.4 匿名函数
如果一个函数只需要一个表达式就行,但是这个表达式会多次调用,那么可不需要专门定义一个标准的函数,使用lambda匿名函数即可。lambda函数有自己的命名空间,不能访问自己参数列表之外或全局命名空间的参数。
1 | lambda [arg1 [, arg2, ..., argn]]: expression |
1 | sum = lambda arg1, arg2: arg1 + arg2 |
4. 模块与包
模块首先是一个含有源代码的文件在Python里以.py结尾,文件里可以有函数的定义、变量的定义或者对象(类的实例化)的定义等等内容。如果一个项目的代码量较大,函数较多,最好把一个文件分为多个文件来管理,这样总程序脉络清晰易于维护和团队分工协作,这就是Python里存在模块的意义所在。模块名就是文件名(不含.py),例如假设有一个模块:xopowo.py那么模块名为xopowo。
但当一个项目的模块文件不断的增多,为了更好地管理项目,通常将功能相近相关的模块放在同一个目录下,这就是包,故包从物理结构上看对应于一个目录,一个特殊要求,包目录下必有一个空的init.py文件,这是包区分普通目录的标签或者说是标志。包下可以又有包称为子包,子包也是一个目录,子包的目录下也得有一个空的init.py文件。这样就构成了分级或者说分层的项目管理体系。
4.1 模块的使用
模块,可是Python自带的、而外安装的或者开发者自己写的,在一个文件里使用模块很简单用import即可,import有点像C语言的include。import语句会在sys中包含的path中去寻找所导入的模块,
1 | >>>import sys |
上面其实已经演示了一种import的使用方法,直接使用import module_name语句会将该模块全部导入。而在使用时,需要明确使用的是模块中的具体哪一个方法。与调用对象的方法类似,使用点运算符号,比如sys.path。
只需要导入模块的某些函数时,需要使用form module_name import fun_name语句。使用该方法导入的模块函数可以直接调用,不需要再指明是哪个模块的函数。如果要导入一个模块中的全部内容,可以使用form module_name import *语句,这样便可以直接使用该模块的全部函数。但是这种方法不太符合规范,不应该经常使用。
4.2 包的使用
包,实际是更大规模的以目录形式存在的模块集合,包可以含子包,包区别于目录是包的目录下有一个空的init.py文件。包和模块一样有Python自带的包,也可以通过工具安装一些包,例如numpy就是数据科学领域比较常用的一个包,需额外安装,当然也可以自己开发一些包。
在使用包中的模块时,也是通过点运算符来调用某一个模块。这样便可以想模块那样,不必担心不同模块之间的全局变量相互影响,也不必担心不同包(库)的模块重名现象。
目录只有包含一个叫做 init.py 的文件才会被认作是一个包,主要是为了避免一些滥俗的名字(比如叫做 string)不小心的影响搜索路径中的有效模块。
5. 文件操作
Python对于文件的操作和其他编程语言大致一样,都是通过open函数去打开某个文件,返回这个文件对象。通过使用文件对象的一些函数方法来读取文件内容,读取完毕后使用close关闭文件。
5.1 open函数参数
open函数一般有两个参数,文件名file和模式mode,但完整格式语法为
1 | open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None) |
参数说明:
- file: 必需,文件路径(相对或者绝对路径)。
- mode: 可选,文件打开模式
- buffering: 设置缓冲
- encoding: 一般使用utf8
- errors: 报错级别
- newline: 区分换行符
- closefd: 传入的file参数类型
- opener:
模式有以下几种:
| 模式 | 描述 |
|---|---|
| t | 文本模式 (默认)。 |
| x | 写模式,新建一个文件,如果该文件已存在则会报错。 |
| b | 二进制模式。 |
| + | 打开一个文件进行更新(可读可写)。 |
| U | 通用换行模式(Python 3 不支持)。 |
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
5.2 读文件
读文件之前需要使用open函数打开该文件,open函数返回该文件对象,之后的文件读取操作就通过该文件对象完成。
1 | filename = "./data.csv" |
read函数会一次性读取所有文件内容,以字符串的形式赋给data,可以使用read(size)来确定一次读多少。手动调用open函数打开的文件一定要记得关闭,因为打开文件会占用操作系统资源,操作系统同时能打开的文件数量也是有限的。
python主要有三个类型的读取函数供选择,分别是read、readline、readlines。
- read可以指定每次读取的最大数量,如果不指定就一次性读取全部,当文件很大的时候是比较占内存的。
- readline一次读取一行,如果数据是按行排列的就可以采用这种方式即可分类又可节约内存。
- readlines从文件当前读写位置读取多行,每行作为一项,因此返回列表。
5.3 读写位置
与文件读写位置相关的函数有两个:tell和seek。tell函数可以返回目前函数的读取位置,seek函数可以调整当前读写位置。
1 | #tell |
seek函数给出从三个位置出发调整读写位置的方法:
1 | seek(offset, [whence]) |
whence 有三个取值,分别是0, 1,2。0是默认值,表示从文件头开始计算偏移,offset需大于0。1表示从当前读写位置计算偏移量,此时offset可正可负。2表示从文件尾计算偏移,当然它的offset需小于0。
1 | >>>filename = "./data.csv" |
5.4 写文件
写文件可以通过write和writelines函数实现,写文件需要使用可写模式打开文件,当需要写入的是一整串字符串时就用write函数即可,若写入的内容可迭代就可以使用writelines,比如列表。使用writelines如果需要换行需要手动添加,不然所有数据都会在一整行。
1 | filename = "./data.csv" |
5.5 CSV文件操作
有的文件通过一些分隔符号,例如逗号、分号、冒号等将一条记录的各个字段分割开,这样的存储数据的方式典型的文件类型有csv文件、xml文件等。
python自带有CSV模块可以方便的读取scv类型的文件。该模块里有一个reader函数,用以读取csv文件内容,返回可迭代类型。
1 | import csv |
reader函数中的参数delimiter代表csv文件中每行的各字段数据用什么分割。例如我们可以将原来是’,‘分割的csv文件读取出来后用’;‘再写回去。
1 | import csv |
上面说到csv.reader是一个可迭代的类型,但并没说明它是python中的什么类型,实际上它是csv里实现的一个对象。将其type打印出来就能发现,上面程序结果如下
1 | ['1', '2', '3', '4', '5'] |
5.6 使用with open
在上面的例子中,每次打开文件后都需要进行关闭,实在是有些麻烦。并且,当打开的文件目录不存在或读写过程中都有可能产生IOError,产生IOError后就不能正常的close文件。为此,我们可能需要使用try-catch语句来调用open函数。
1 | try: |
这谁顶得住?所以,python为我们提供了一个简单的方法来打开文件,它可以帮助我们管理open与close。使用方法如下
1 | with open(filename, 'r') as fp: |
这样with语句中的文件读写操作都与前面的一样了,不用写close了,非常方便。
Reference:
[1] Python学习园
[2] python3教程
[3] with open语句